Jinyi Liu刘金毅
Reliable, long-horizon LLM agents.
I work at the intersection of RL, LLM post-training, and agentic systems — building agents that reason reliably, retain long-horizon memory, and act effectively in real-world and scientific tasks.
Two roads diverged in a wood, and I—
I took the one less traveled by,
and that has made all the difference.
News
- 🎉 Paper accepted by SIGKDD 2026 Research Track: PACE.
- 🚀 Released ScriptMem, a memory framework driven by real-world scripts.
- 🏆 MemoraX AI memory system achieves SOTA on LoCoMo-Refined with 82.65, outperforming the next best by over 30%.
- 📝 Three papers accepted by ICLR 2026: ReMix, CellAgent, and From Seeing to Doing.
- 🧠 Two workshop papers accepted at ICLR 2026: AgentMemoryBench and DistRLVR.
- 📝 Paper accepted by ACM TheWebConf 2026 Industry: AFE-Master.
- 🔥 Released our beginner-friendly LLM Agent tutorial (website & PDF).
- 🎤 The 137th RLCHINA Paper Seminar hosted!
Selected Publications
The full publication archive remains available from the site navigation.
DistRLVR
RLVR · First author · SPOT@ICLR 2026Distributional RL framework for LLM post-training with verifiable rewards, modeling token-level return distributions for more informative advantages.
ReMix
Post-training · First author · ICLR 2026Off-policy reinforcement finetuning for LLMs that reuses historical rollouts to make reasoning-oriented post-training more data efficient.
CellAgent
AI4S Agents · First author · ICLR 2026LLM-driven multi-agent system for natural-language single-cell and spatial transcriptomics analysis, with a live system serving real user requests.
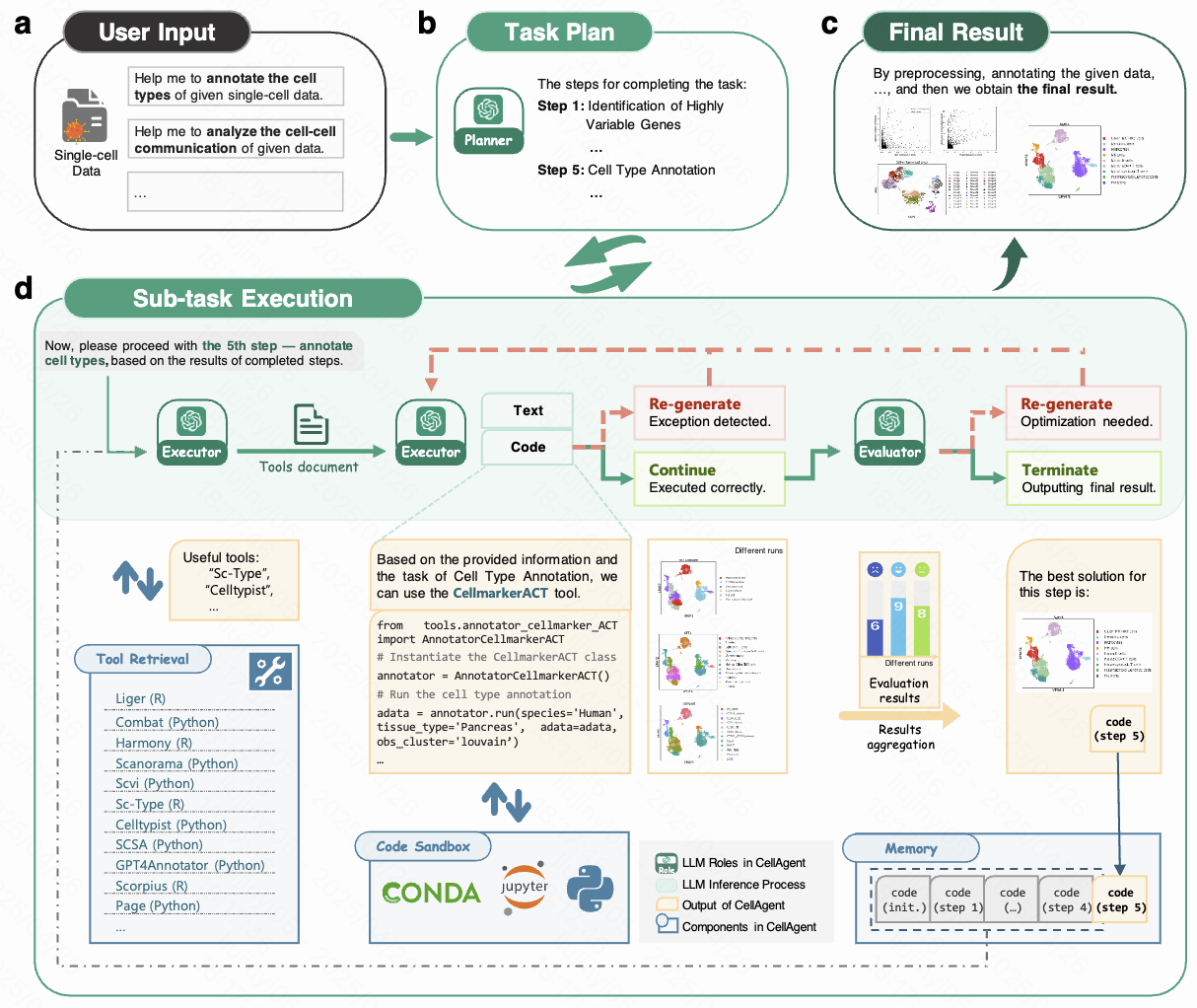
AgentMemoryBench
Agent Memory · First author · LLA@ICLR 2026Unified benchmark for continual agent memory, measuring improvement, retention, forgetting, transfer, and conflict resolution across long-horizon scenarios.
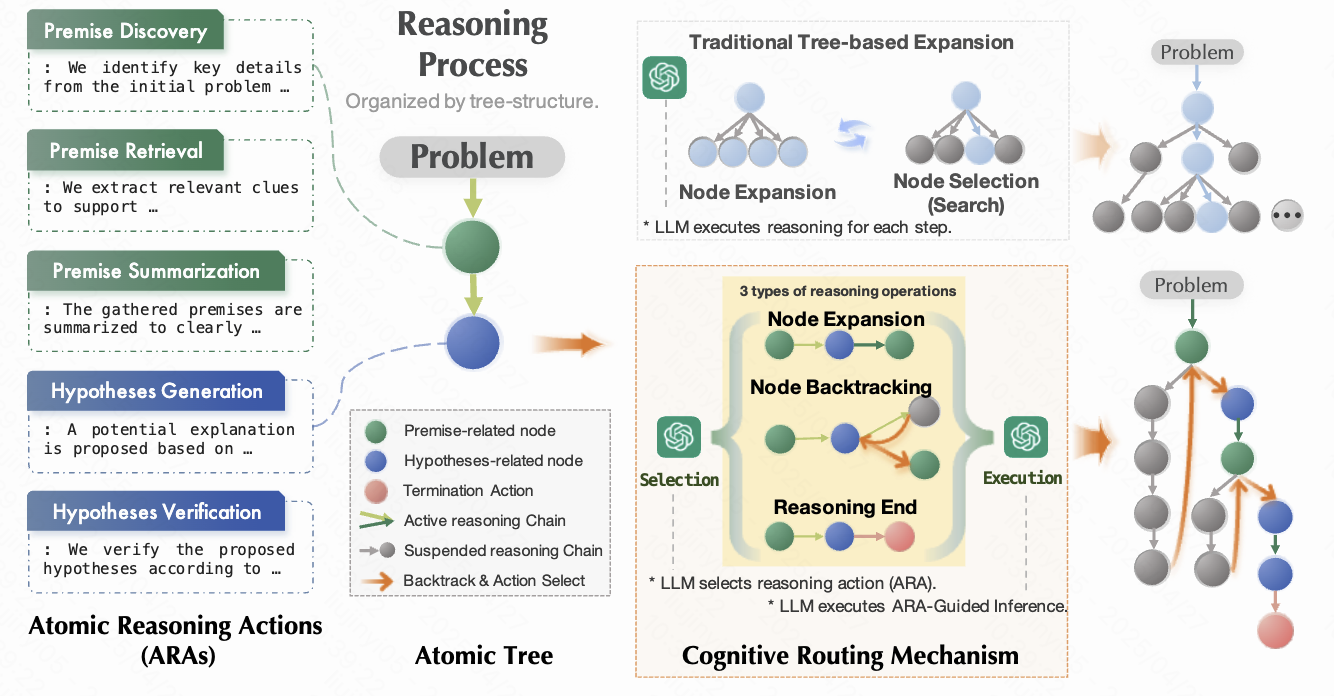
Atomic Reasoner
Reasoning · First authorFine-grained reasoning framework that decomposes deliberation into atomic cognitive operations without relying on heavyweight search or external tools.
PPE
Preference RL · First author · NeurIPS 2025Improves reward models for preference-based RL through proximal policy exploration, yielding more robust human-preference alignment.
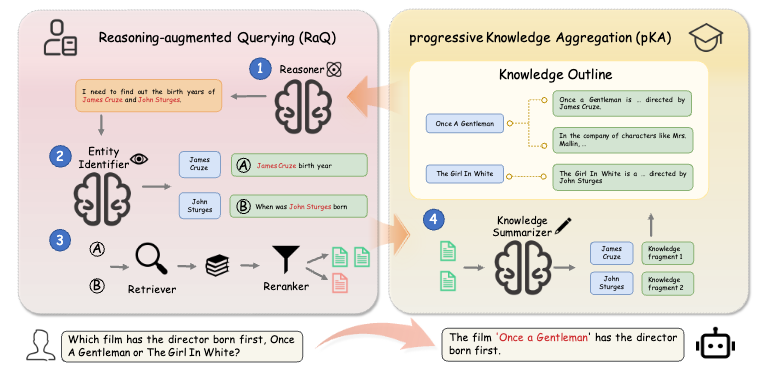
DualRAG
Reasoning & Retrieval · Co-author · ACL 2025Dual-process framework that tightly couples retrieval and reasoning for multi-hop question answering, achieving stronger generalization than retrieve-then-read pipelines.
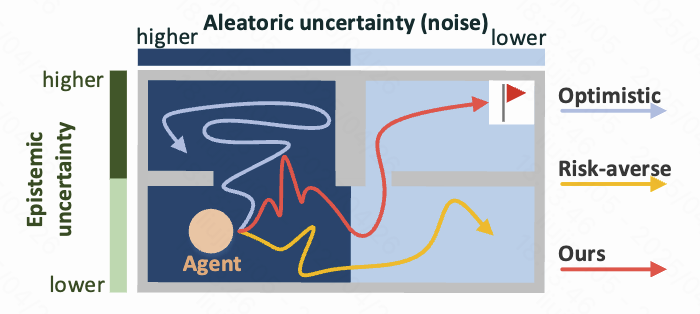
OVD-Explorer
RL Exploration · First author · AAAI 2024Noise-aware optimistic exploration method that separates useful uncertainty from stochastic noise in deep reinforcement learning.
PTR
Offline RL · First author · AAMAS 2024 OralTrajectory-level view of data sampling for offline RL, showing that sample organization alone can substantially improve learning efficiency.
CriticGPT
Embodied AI · First author · RL+LLMs@AAAI 2024Multimodal LLM used as a critic for robot manipulation, providing AI feedback that improves planning and execution in robotic tasks.
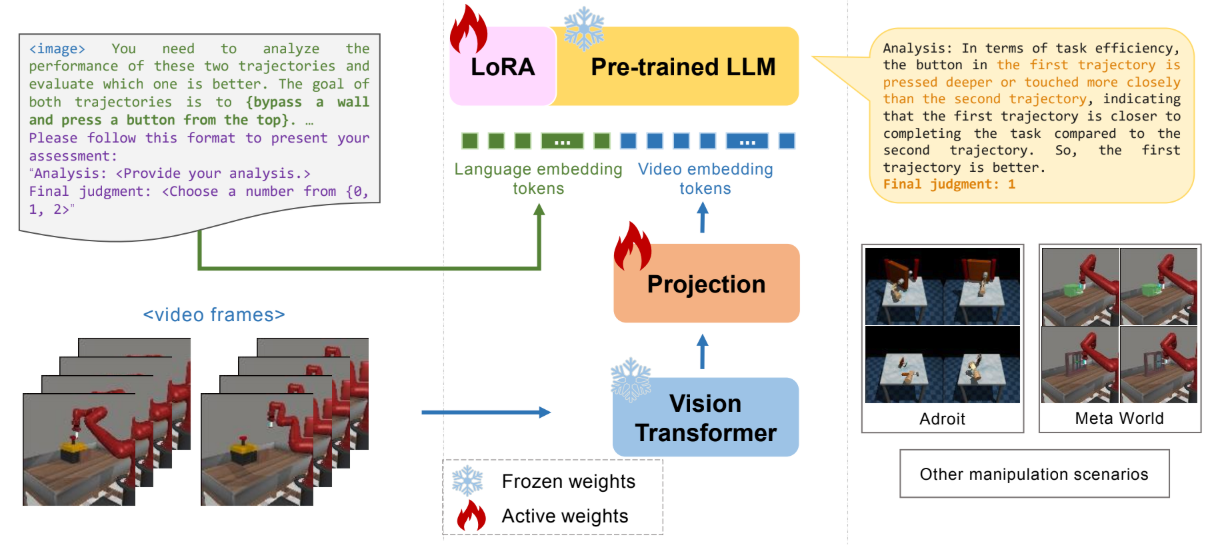
Projects
CellAgent
A natural-language interface for single-cell and spatial transcriptomics analysis, built as a usable research system rather than only a paper artifact.
2000+ requests Public learning resourceLLM Agent Tutorial
A beginner-friendly tutorial hub for LLM-based agents, connecting conceptual foundations with hands-on examples and practical design patterns.
Tutorial + examples RLHF infrastructureUni-RLHF
A public platform and benchmark suite for reinforcement learning with diverse human feedback.
Platform + benchmark MemoraX · Agent memory benchmarkScriptMem
A long-term memory benchmark built from scripted narratives (Friends, 12 Angry Men). MemoraX ranks 1st at 60.3% — 17.4 percentage points ahead of the next-best system.
#1 · 60.3% acc (+17.4pp gap)Talks
- 面向复杂推理的大语言模型智能体关键技术研究 Northwestern Polytechnical University
- 强化学习驱动的大模型微调 Research Frontier Seminar, Beijing
- A Trajectory Perspective on the Role of Data Sampling Techniques in Offline Reinforcement Learning AAMAS (Auckland)
- 基于原子认知操作的大语言模型结构化推理框架 RLCHINA Paper Seminar
- CriticGPT: Multimodal LLM as a Critic for Robot Manipulation AAAI
- 大语言模型驱动的单细胞测序数据分析自主智能体 RLCHINA Paper Seminar
- 深度强化学习算法、发展与前沿应用 Lanshi Ventures
Timeline
Research Exchange
MemoraX AI (Shenzhen)
Algorithm Research Intern · AI4S Center
Shanghai AI Lab
Dr. Shuyue HuRL-based LLM post-training and agent training. Representative work: DistRLVR, LLM Agent Tutorial.
Ph.D. Student
Tianjin University
Prof. Jianye Hao, Yan Zheng, Hongyao TangTJU DRL Lab. LLM post-training, memory, reasoning, and agentic systems.
Algorithm Research Intern · Kuaiyi LLM
Kuaishou
Dr. Hangyu MaoLLM-agent reasoning, DualRAG, Atomic Reasoner, GUI agents.
Algorithm Research Intern
NetEase Fuxi AI Lab
Dr. Yujing HuGame AI and RL decision-making: offline RL, exploration, preference-based RL.
M.Sc. Student
Tianjin University
Prof. Jianye HaoTJU DRL Lab. Deep reinforcement learning and multi-agent decision-making.
B.Sc. · Software Engineering
Northeastern University
Recommended for graduate study. Outstanding Bachelor's Thesis Award, Top 1%.
Honors and Service
Selected Honors
2026 🏅 ICML 2026 Gold Reviewer
2025 🥇 CSIG Science and Technology Progress Award, First Prize 国家级学会一等奖 · 唯一学生完成人
2025 🥇 Siyuan-Juebian Intelligent Algorithm Challenge, First Prize
2025 🥉 ICAIS AI Scientist Challenge, Research Track — Global 3rd Place (Top 3)
2025 🏅 AAMAS 2025 Distinguished PC Member
2024 🎓 Academic First-class Scholarship (Top 10%), Tianjin University
2023 📜 iFlyTek Spark "Prompt Engineer" Certification
2022 🥈 Silver Award, 8th China International "Internet+" Innovation and Entrepreneurship Competition, Tianjin Division 第三完成人
2019 📝 Outstanding Bachelor's Thesis Award (Top 1%), Northeastern University
Academic Service
🙋♂️ Conference PC member NeurIPS (2025–)ICLR (2025–)AAAI (2025–)ICCV (2025–)ICML (2025–)ECAI (2025–)IJCAI (2024–)NeurIPS D&B Track (2024–)AAMAS (2023–)CIKM (2022)
Journal reviewer IEEE TNNLS, Machine Learning, Quantum Machine Intelligence, SIVP
Community 🤝 RL China student liaison✍️ Zhihu writer "嗟嗟" — sharing RL and LLM research notes🙋♂️ Conference Committee Volunteer · DAI 2022
Contact
- Collaboration
Open to conversations on LLM post-training, RL, agents, and AI4S.
- PhD / Interns
TJU DRL Lab is welcoming motivated research interns and prospective MS/PhD students.
- MemoraX AI
MemoraX AI is open for collaboration on Agent / Memory research — intern, full-time, or research partnership.