Improving Reward Models with Proximal Policy Exploration for Preference-Based Reinforcement Learning
A reward-modeling approach for preference-based reinforcement learning built on proximal policy exploration.
Sep 26, 2025
Optimizing Reward Models with Proximal Policy Exploration in Preference-Based Reinforcement Learning
A preference-based reinforcement learning study on improving reward models with proximal policy exploration.
Jul 1, 2024
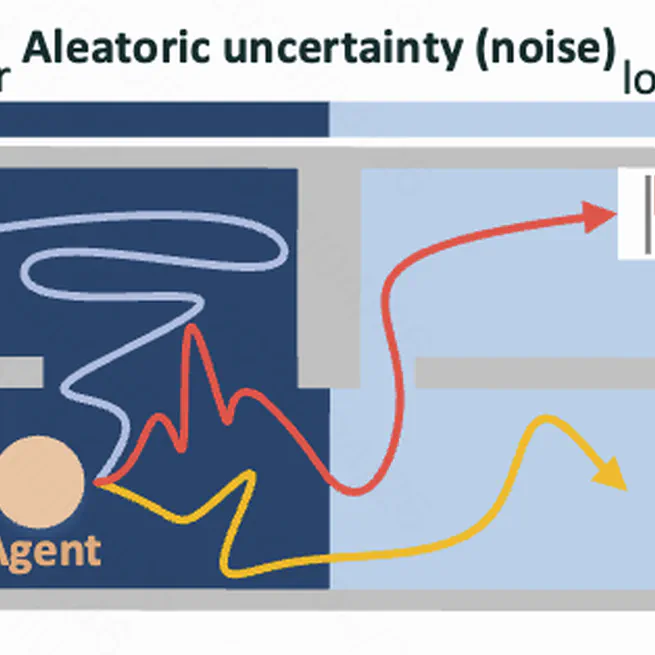
Ovd-explorer: Optimism should not be the sole pursuit of exploration in noisy environments
We propose Optimistic Value Distribution Explorer (OVD-Explorer) to achieve a noise-aware optimistic exploration for continuous control.
May 1, 2024
A trajectory perspective on the role of data sampling techniques in offline reinforcement learning
Organizing samples in a trajective manner can improve the learning efficiency for offline RL algorithms.
May 1, 2024
Enhancing robotic manipulation with AI feedback from multimodal large language models
A study of how multimodal LLM feedback can improve robotic manipulation planning and execution.
Feb 1, 2024
vMFER: Von Mises-Fisher experience resampling based on uncertainty of gradient directions for policy improvement
An experience resampling method that uses gradient-direction uncertainty for more stable policy improvement.
Jan 1, 2024
Uni-RLHF: Universal Platform and Benchmark Suite for Reinforcement Learning with Diverse Human Feedback
A unified platform and benchmark suite for reinforcement learning with diverse human feedback.
Jan 1, 2024
ENOTO: improving offline-to-online reinforcement learning with Q-ensembles
An offline-to-online reinforcement learning method that improves transition efficiency with Q-ensembles.
Jan 1, 2024
OSCAR: OOD State-Conservative Offline Reinforcement Learning for Sequential Decision Making
An offline reinforcement learning method that stays conservative on out-of-distribution states for sequential decision-making.
Jan 1, 2023
Exploration in deep reinforcement learning: From single-agent to multiagent domain
A survey of exploration methods in deep reinforcement learning, spanning single-agent and multi-agent settings.
Jan 1, 2023