Squeeze the Soaked Sponge: Efficient Off-policy RFT for Large Language Model
ReMix brings off-policy reinforcement finetuning to LLM post-training by reusing rollout data from past policies, dramatically reducing training cost while staying competitive on math reasoning benchmarks.
Jan 5, 2026
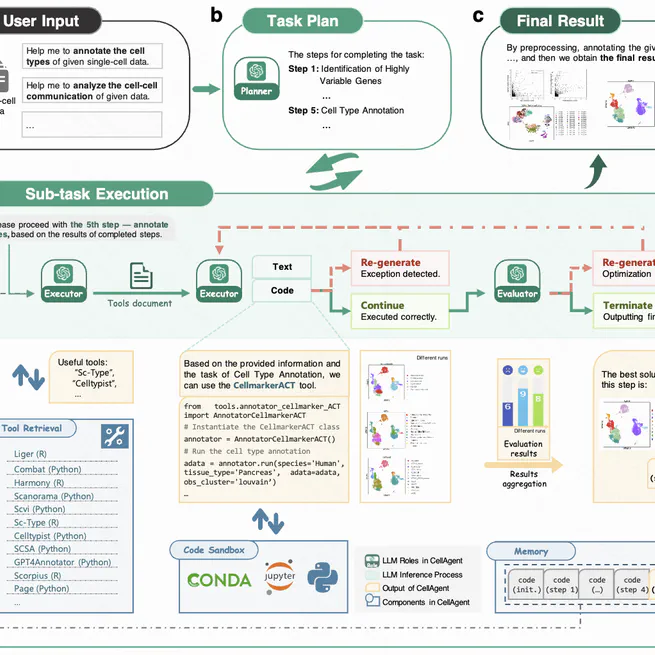
CellAgent: LLM-Driven Multi-Agent Framework for Natural Language-Based Single-Cell Analysis
An LLM-driven multi-agent system for end-to-end single-cell and spatial transcriptomics analysis through natural language, combining hierarchical planning, expert tools, and self-reflective optimization.
Jan 4, 2026
From Seeing to Doing: Bridging Reasoning and Decision for Robotic Manipulation
FSD connects spatial visual reasoning with robotic action by generating structured intermediate representations that improve generalization on unseen manipulation tasks.
Jan 3, 2026
Benchmarking Continual Agent Memory for Online Learning, Transfer, and Forgetting
AgentMemoryBench is a unified benchmark for continual agent memory that measures improvement, retention, forgetting, transfer, and conflict resolution over time, together with a multi-memory baseline called MEMs.
Jan 2, 2026
Beyond Scalar Critics: A Distributional Perspective on Reinforcement Learning with Verifiable Rewards for LLMs
DistRLVR is a distributional RL framework for LLM post-training with verifiable rewards that models token-level return distributions and uses tail-aware advantages to improve sample efficiency and reasoning performance.
Jan 1, 2026
Improving Reward Models with Proximal Policy Exploration for Preference-Based Reinforcement Learning
A reward-modeling approach for preference-based reinforcement learning built on proximal policy exploration.
Sep 26, 2025
Key Decision-Makers in Multi-Agent Debates: Who Holds the Power?
Analyzes mediator roles and decisive voices within multi-agent debate frameworks, revealing how influence shifts throughout deliberation.
Feb 15, 2025
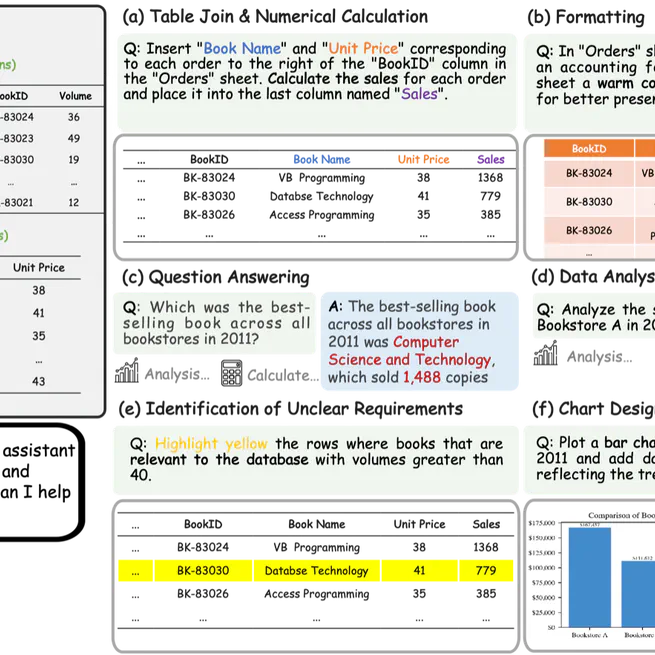
SheetAgent: towards a generalist agent for spreadsheet reasoning and manipulation via large language models
SheetAgent is a generalist LLM agent for spreadsheet reasoning and manipulation across realistic multi-step spreadsheet tasks.
Jan 8, 2025
Optimizing Reward Models with Proximal Policy Exploration in Preference-Based Reinforcement Learning
A preference-based reinforcement learning study on improving reward models with proximal policy exploration.
Jul 1, 2024
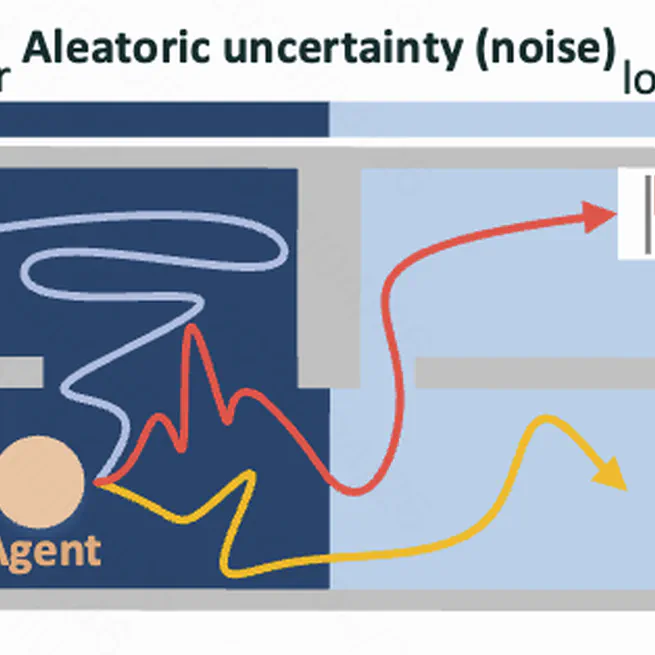
Ovd-explorer: Optimism should not be the sole pursuit of exploration in noisy environments
We propose Optimistic Value Distribution Explorer (OVD-Explorer) to achieve a noise-aware optimistic exploration for continuous control.
May 1, 2024