Reliable reasoning
I design reasoning frameworks that make language models more consistent, more controllable, and more trustworthy on complex tasks.
Reliable reasoning and decision-making
with LLM post-training, reinforcement learning, and agents.
Signature Themes
Three directions that define how I think about reliable language-model systems and their real-world use.
I design reasoning frameworks that make language models more consistent, more controllable, and more trustworthy on complex tasks.
I study reinforcement-learning-based post-training methods that improve capability while reducing cost and instability.
I build agent systems that translate language-model reasoning into useful workflows for research, analysis, and discovery.
Research
A curated set of papers that best represent my current work across reasoning, agent systems, and AI for science.
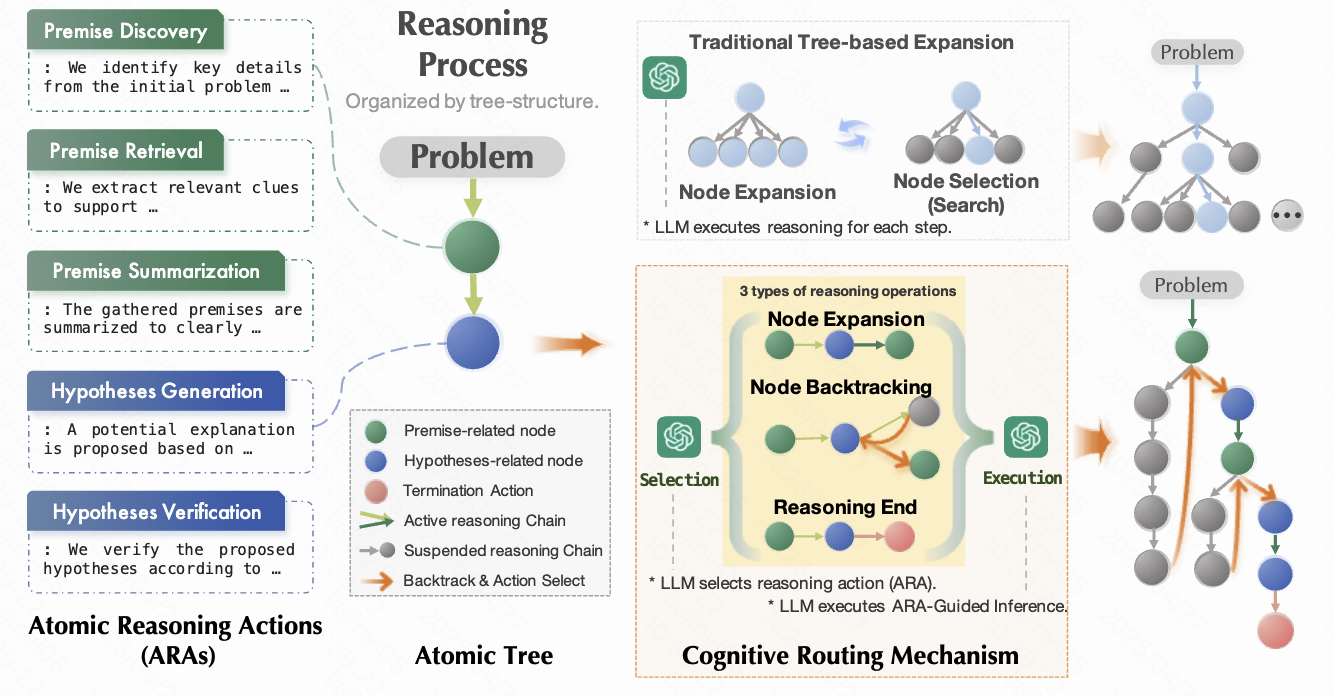
Breaks complex reasoning into small atomic steps so language models can reason more reliably without relying on heavyweight search or tool orchestration.
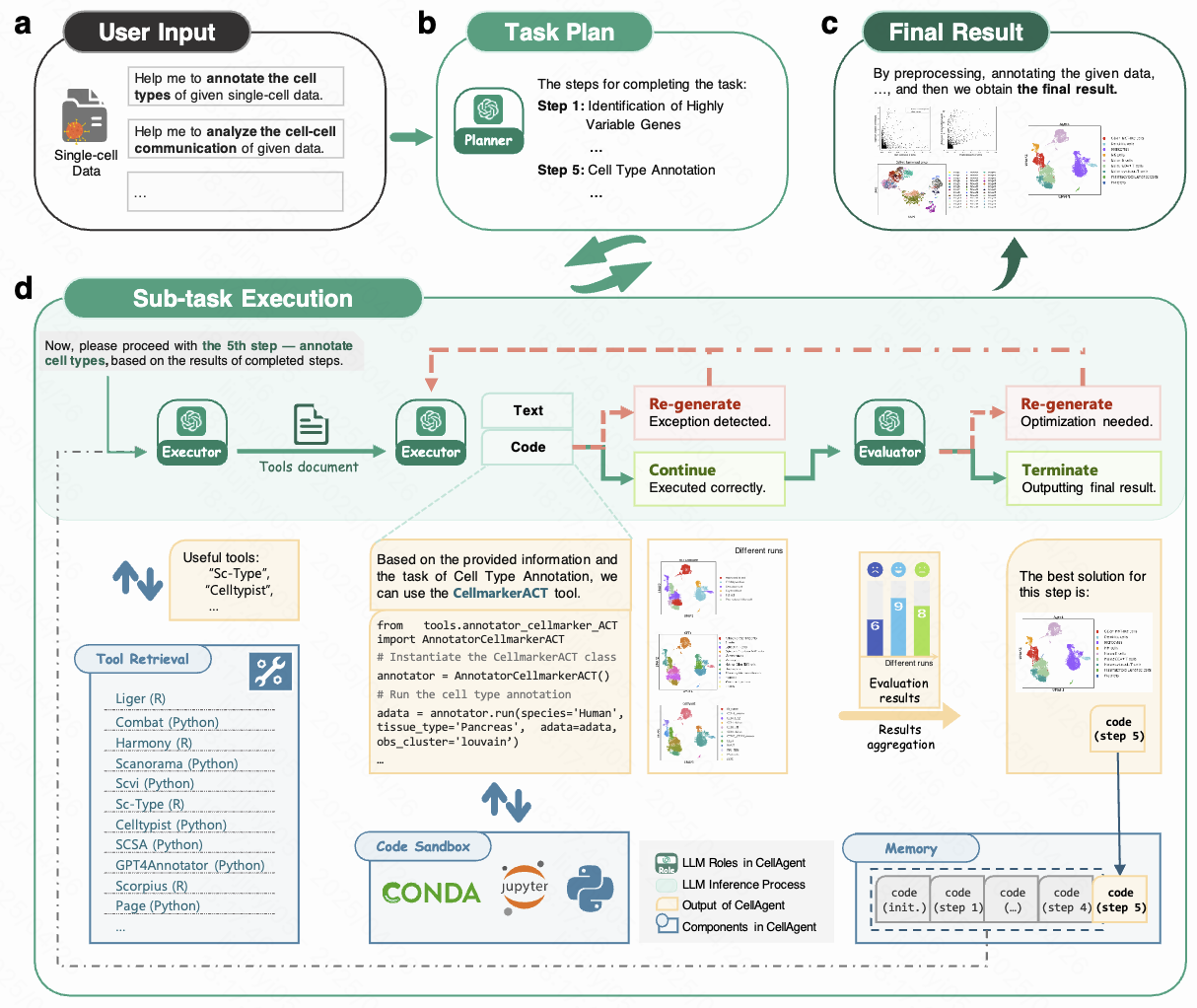
Lets researchers run end-to-end single-cell and spatial transcriptomics analysis through natural language, reducing programming overhead without sacrificing result quality.
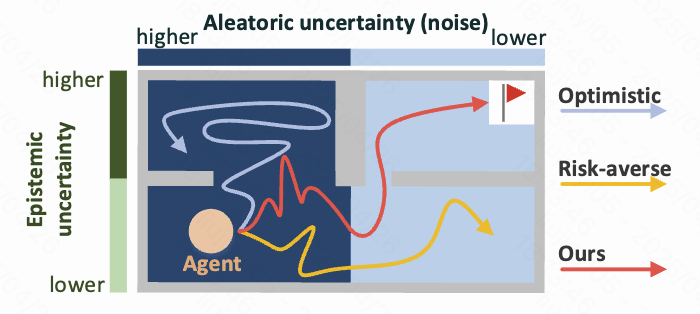
Improves exploration in noisy reinforcement learning settings by separating genuinely useful uncertainty from stochastic noise that would otherwise mislead the agent.
Systems
Selected systems and learning artifacts that turn research ideas into tools people can actually use.
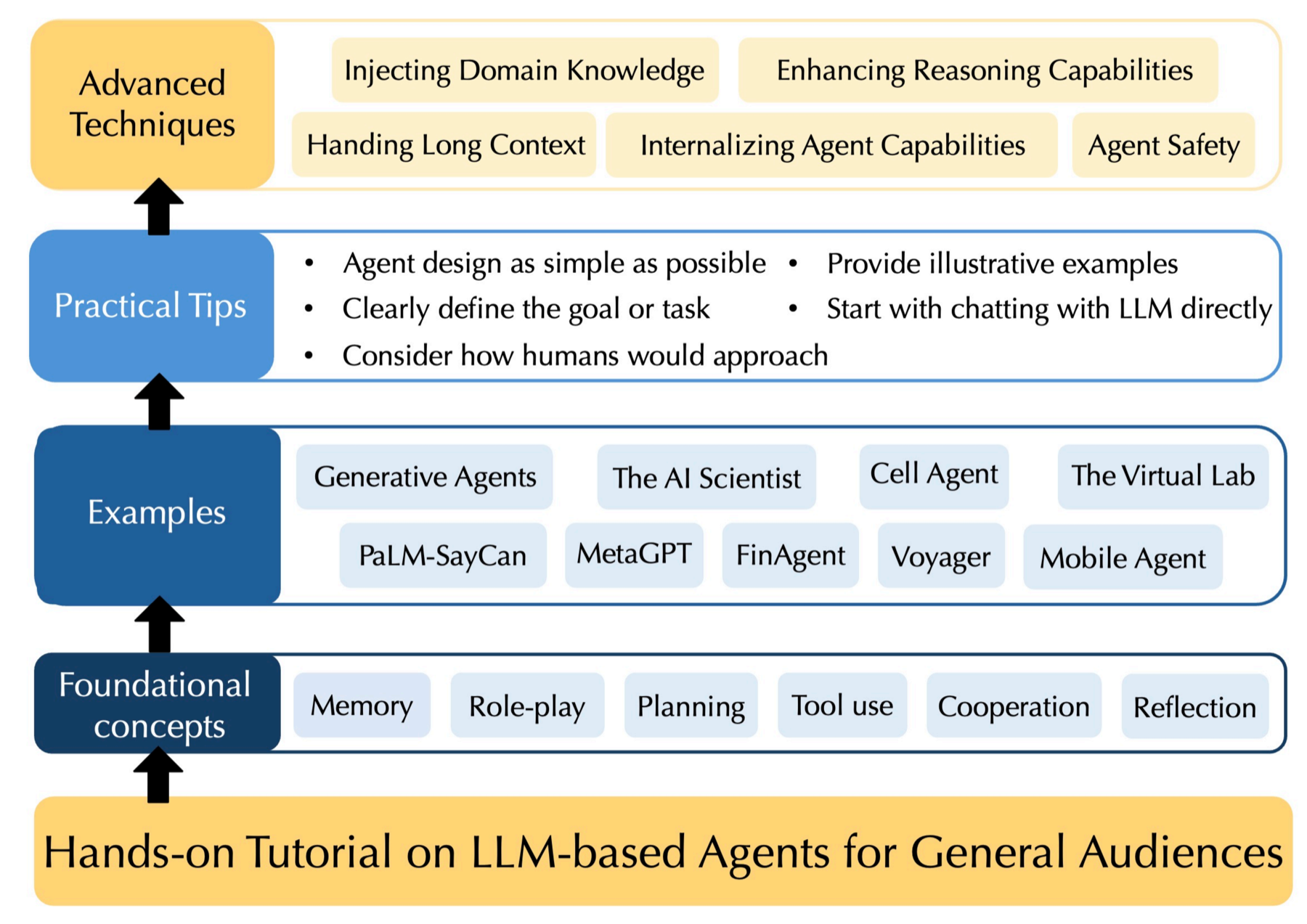
Project page for the LLM Agent Tutorial website, highlighting the public learning resource, companion materials, and entry points for readers.


Updates
Recent milestones across papers, systems, tutorials, and community work.
Trajectory
A brief view of research training, industry collaboration, and selected recognition.
Shanghai AI Lab (advised by Shuyue Hu)
Kuaishou (advised by Hangyu Mao)
NetEase (advised by Yujing Hu)
CSIG
AAMAS 2025
Tianjin University